








Igeekphone News, June 9th: Xiaomi, in collaboration with TileRT, has officially launched MiMo-V2.5-Pro-UltraSpeed, achieving a landmark breakthrough in the industry: Based on a trillion-parameter large model, on a single standard 8-card general-purpose GPU node, the text generation speed has been increased to 1000 tokens per second for the first time.
Even the peak rate can reach 1200 tokens per second. There is no need to customize dedicated chips throughout the process, significantly lowering the implementation threshold for ultra-fast AI inference.
This version has launched a limited-time API service in synchronization. The pricing is three times that of the original MiMo-V2.5-Pro, but the generation speed has increased by approximately 10 times, presenting a remarkable cost-performance advantage.
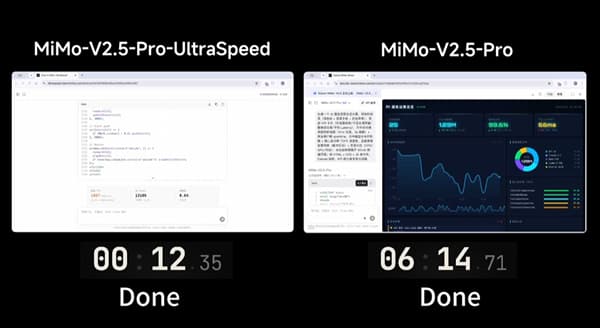
Due to the limitation of high-speed reasoning resources, the service is temporarily available on a subscription basis. The trial period is from June 9th to 23rd, 23:59 Beijing Time. The platform will give priority to reviewing enterprises and professional developers with actual business needs. Ordinary users can freely experience the conversation function through the dedicated webpage.
The daily queue limit for a single account is 10 times, and the maximum duration of a single session is 30 minutes. If the session is idle for 5 minutes, it will automatically be disconnected to ensure fair resource allocation.
This performance leap is achieved through the deep collaborative design of models and systems. The core innovations include three major technological advancements:
The first one is the FP4 quantization technology. According to the characteristics of the model’s MoE architecture, only the expert layer, which accounts for the majority of the parameters, undergoes lossless FP4 quantization. The remaining modules retain their original precision. This not only reduces memory usage and alleviates bandwidth pressure but also ensures that the overall capability of the model remains largely unchanged.
The second is DFlash block parallel speculative decoding. It abandons the traditional serial decoding mode and can predict an entire text block at a time. In scenarios such as code and mathematical reasoning, it can confirm an average of 6-7 tokens per round, significantly improving the decoding efficiency.
Thirdly, by relying on the TileRT inference system, the GPU execution architecture is restructured. Persistent cores and heterogeneous pipelines are adopted to eliminate the delay caused by operator switching, allowing the hardware computing power to remain fully operational at all times.

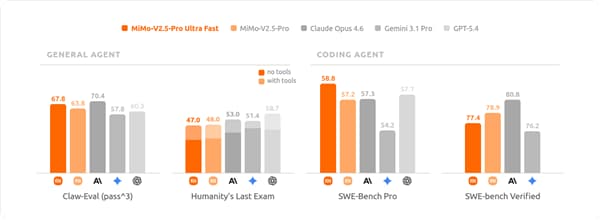
The extremely fast reasoning ability has also reshaped the application scenarios of AI. The ultra-high speed enables parallel reasoning of models, autonomous error correction, and improvement of logical reasoning quality; it significantly alleviates the waiting and lag in code generation, releasing the productivity of programming agents; at the same time, it enables the deployment of trillion-parameter large models in high-frequency quantitative trading, real-time anti-fraud, medical image analysis and other real-time decision-making scenarios with millisecond latency.