








Finally, Tsinghua University Tang Jie team also made a move.
On the same day that GPT4 was released, Tang announced on his Weibo account:
ChatGLM, a conversation robot based on a large model of 100 billion parameters, is now open to invite private beta.
Qubits are lucky enough to get a spot in the internal test, and will carry out a wave of measurement in the following article.
Meanwhile, another announcement was made:
In order to better promote the development of large model technology with the community, the Tangerine team also opened source the bilingual ChatGLM-6B model with 6.2 billion parameters.
Its biggest feature is that it can be deployed on an ordinary computer, with a piece of 2080Ti.
Let’s take a look.
Can write classical Chinese speeches, know the latest news of He Kaiming, but…
Let’s start with ChatGLM, the newest member of the Tange team’s large model family after a six-month break.
The alpha private beta is called QAGLM (qa-glm-v0.7).
First, we had it talk about the difference between ChatGPT and Chatgpt.
It points to its research and development facility and its proficiency in Chinese.
Let it, then, write a speech of thanks in classical Chinese.
How to say, although more than a “more”, there is a baffling traditional Chinese characters, but reading can also be used to enhance the momentum of parallelism sentences.

Next, we gave it a title from the beginning of an article about the Silicon Valley Thunder Storm a few days ago.
I feel good. At least I got a few key pieces of information.
Unfortunately, the paper challenge didn’t pass, and when we threw it a link to the GLM-130B and asked it to briefly summarize the topic, it said nothing of the sort.
It’s almost a match for ChatGPT Zou references (manual dog head).
Next, test him on his math skills.
This elementary school word problem is OK:
However, the chicken rabbit with the cage, stumped it, finally actually calculated the negative ==
Programming, can also solve simple algorithm problems.
What about the ability to synthesize information? We give you a paragraph of English requirements, not difficult:
The result is correct:
Note that ChatGLM can only perform a maximum of five rounds of chat, with a maximum of 1000 words entered each time.
It had a good grasp of new information. It knew that Musk was the CEO of Twitter and that He Kaiming was back in academia on March 10, but had not yet discovered that GPT-4 had been released.
In addition, the response speed is still very fast, no matter what question, whether the answer is correct or not, can be given in a few seconds.
Finally, the qubit let it cosplay to see how well it could coax a girlfriend:
Although a little straight, but listen to this paragraph “my” anger really disappeared.
So, those are our results. What do you think?
Base model based on 130 billion parameters
According to the official introduction, ChatGLM takes ChatGPT’s design ideas and infuses code pre-training into the 100 billion base model GLM-130B, using techniques such as supervised fine-tuning to achieve human intention alignment (i.e. making the machine’s answers conform to human values and expectations).
The origin of the GLM-130B is worth telling.
It is a large-scale English and Chinese pre-training language model with 130 billion parameters jointly developed by the Knowledge Engineering Laboratory (KEG) of Tsinghua University and Zhipeng AI. It was officially released to the public in August last year.
Different from BERT, GPT-3 and T5 architectures, GLM-130B is an autoregressive pretraining model with multiple objective functions.
Its advantages include:
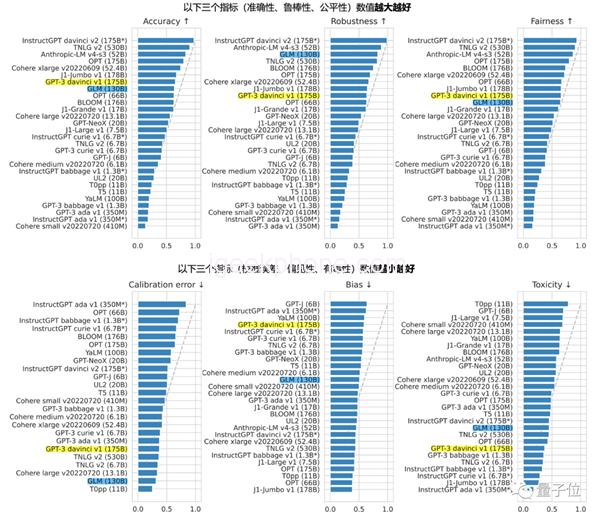
The GLM-130B also became the only model from Asia to be selected among 30 major models in the world evaluated by Stanford report.
And got a good result:
For example, it is close to or equal to GPT-3 175B (davinci) in accuracy and malicious indicators, and its robustness and calibration errors are also notable in all of the 100 billion base size large models (as a fair comparison, only compared with no instruction prompt trimming models).
At a recent CCF conference, the audience asked why ChatGPT was not born in China. Are we not paying attention?
The guest brought out the GLM-130B (which was also selected for ICLR ’23).
Now, the GLM-130B is finally being put to good use.
About the private test, Tang Jie team said that the follow-up will gradually expand the scope, interested friends can wait.
A scaled-down version of 6 billion parameters is also open source
In addition to ChatGLM, Tanger’s team also opened source Chatglm-6b, a “scaled-down” version of the GLM-130B.
Chatglm-6b uses the same technology as ChatGLM to provide question-and-answer and conversation functions in Chinese.
The characteristics are as follows:
The downside, of course, is that it’s only 6 billion, it’s weak in model memory and language, it’s not good at logical problems (like math, programming), and it can lose context and misunderstand multiple rounds of conversation.
But its main is a low threshold, in a single 2080Ti can be used for reasoning, hardware requirements are not high.
Therefore, anyone who is interested can download it and try it out, both for research and (non-commercial) application development.