








The MLCommons community released the latest MLPerf 2.1 benchmark results. The new round of benchmarks has nearly 5,300 performance results and 2,400 power consumption measurements, which are 1.37 times and 1.09 times higher than the previous round, respectively. , the scope of application of MLPerf is further expanded.
Alibaba, ASUS, Azure, Biren Technology, Dell, Fujitsu, Gigabyte, H3C, HPE, Inspur, Intel, Krai, Lenovo, Moffett, Nettrix, Neural Magic, NVIDIA, OctoML, Qualcomm, SAPEON, and Supermicro are all tested in this round contributors.
Among them, NVIDIA still performed well, taking H100 to participate in the MLPerf test for the first time, and set a world record in all workloads.
NVIDIA released the H100 GPU based on the new architecture NVIDIA Hopper in March this year, which achieved an order of magnitude performance leap compared to the NVIDIA Ampere architecture launched two years ago.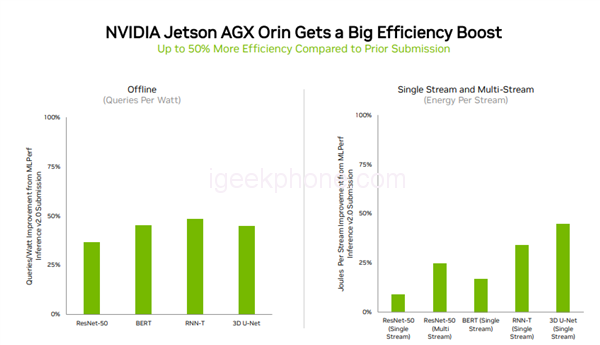
Huang Renxun once said at GTC 2022 that 20 H100 GPUs can support traffic equivalent to the global Internet, which can help customers launch advanced recommendation systems and large-scale language models that run data inference in real-time.
The H100, which many AI practitioners are looking forward to, was originally scheduled to be officially shipped in the third quarter of 2022. It is currently in a state of accepting reservations. The actual usage of users and the actual performance of the H100 are still unknown, so it can pass the latest round of MLPerf tests. Score early to feel the performance of the H100.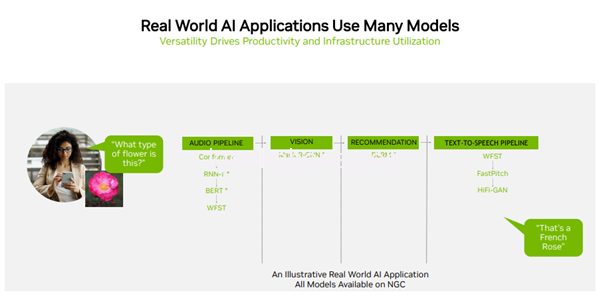
In this round of testing, compared with Intel Sapphire Rapids, Qualcomm Cloud AI 100, Biren BR104, SAPEON X220-enterprise, NVIDIA H100 not only submitted the test scores of all six neural network models in the data center but also in single server and offline scenarios. Demonstrated leadership in throughput and speed.
Compared with the NVIDIA A100, the H100 showed a 4.5x performance improvement in one of the largest and most performance-demanding MLPerf models, the BERT model for natural language processing, and 1 in all five other models. Up to 3x performance improvement.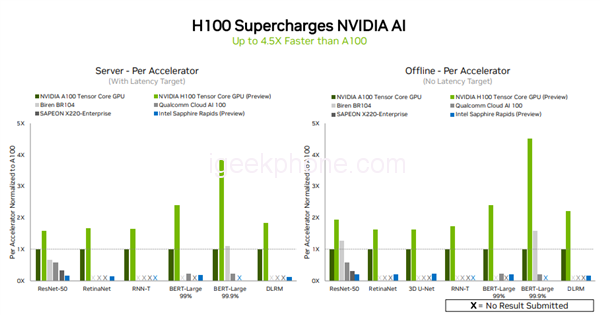
The reason why the H100 can perform well on the BERT model is mainly due to its Transformer Engine. Among other products that also submitted scores, only Biren BR104 has more than doubled the performance of NVIDIA A100 under the ResNet50 and BERT-Large models in offline scenarios, and none of the other products that submitted scores surpassed A100 in performance.
In the data center and edge computing categories, the A100 GPU’s test results are still good. Thanks to the continuous improvement of NVIDIA AI software, the A100 GPU achieves 6 times the performance compared to the debut of MLPerf in July 2020. promote.
Since users usually need to use many different types of neural networks to work together in practical applications, for example, an AI application may need to understand the user’s voice request, classify images, make suggestions, and then respond with voice, each step needs to use Different AI models.
Because of this, MLPerf benchmarks cover popular AI workloads and scenarios including computer vision, natural language processing, recommender systems, speech recognition, and more, in order to ensure users get reliable and deployment-flexible performance.
This also means that the more models covered by the submitted test scores, the better the results, and the more versatile it’s AI capabilities are.
In this round of testing, NVIDIA AI remains the only platform capable of running all MLPerf inference workloads and scenarios in data centers and edge computing.
On the data center side, both the A100 and H100 submitted six model test scores.
In edge computing, NVIDIA Orin ran all MLPerf benchmarks and was the most tested chip of all low-power SoCs.
Orin is the integration of NVIDIA Ampere architecture GPU and Arm CPU core into a single chip, which is mainly used for robots, autonomous machines, medical machinery, and other forms of edge-embedded computing.
Currently, Orin has been used in the NVIDIA Jetson AGX Orin developer kit as well as robotics and autonomous system generation mock tests and supports the full NVIDIA AI software stack, including autonomous vehicle platforms, medical device platforms, and robotics platforms.
Compared to its debut at MLPerf in April, Orin is 50% more energy efficient, running 5x and 2x faster than the previous generation of Jetson AGX Xavier modules, respectively.
The pursuit of general purpose NVIDIA AI is being supported by the industry’s broad machine learning ecosystem. In this round of benchmarking, more than 70 submissions were run on the NVIDIA platform. For example, Microsoft Azure submitted results running NVIDIA AI on its cloud service.
Read Also: NVIDIA RTX 4090 Rendering Leaked: Double The Performance
Do not forget to follow us on our Facebook group and page to keep you always aware of the latest advances, News, Updates, review, and giveaway on smartphones, tablets, gadgets, and more from the technology world of the future.